问: 我要在 kali 上新建一个虚拟环境。
好的,在 Kali Linux 上为 Python 项目创建一个独立的虚拟环境是一个非常好的习惯,可以避免不同项目之间的依赖冲突。
Kali 自带了 Python 3,我们将使用 Python 3 自带的 venv 模块来创建虚拟环境。这是最推荐、最标准的方式。
以下是详细步骤:
第一步:更新软件包列表并安装 venv (如果需要)
首先,打开你的终端。虽然 Kali 通常已经安装了必要的工具,但执行一次更新并确保 python3-venv 包存在是个好习惯。
# 更新软件包列表
sudo apt update
# 安装 python3-venv 包(如果系统中还没有的话)
sudo apt install python3-venv -y-y 参数会自动确认安装,无需手动输入 ‘Y’。
第二步:选择项目目录并创建虚拟环境
-
进入或创建你的项目文件夹。假设你想把项目放在
~/projects/my_scraper目录下。# 创建一个名为 projects 的文件夹(如果还没有的话) mkdir -p ~/projects # 进入该目录 cd ~/projects # 创建你的具体项目文件夹,例如 my_scraper mkdir my_scraper # 进入你的项目文件夹 cd my_scraper -
创建虚拟环境。在项目文件夹内,使用以下命令创建一个名为
venv的虚拟环境。venv是一个通用的、大家默认的虚拟环境文件夹名称,你也可以换成别的,比如.env。# python3 -m venv [虚拟环境文件夹的名称] python3 -m venv venv执行后,你会看到当前目录下多出了一个名为
venv的文件夹,里面包含了独立的 Python 解释器和包管理工具。
第三步:激活虚拟环境
创建好之后,你需要“激活”它,这样你的终端会话就会开始使用这个新环境,而不是系统的全局 Python 环境。
# 激活 venv 环境
source venv/bin/activate激活成功后,你会看到你的终端提示符前面多出了 (venv) 的字样,像这样:
(venv) kali@kali:~/projects/my_scraper$
这就表示你已经成功进入了虚拟环境!
第四步:在虚拟环境里工作
现在,你可以在这个纯净的环境里为所欲为了。
-
检查 Python 和 Pip 版本:
# 确认使用的是虚拟环境里的 python which python # 应该会输出类似: /home/kali/projects/my_scraper/venv/bin/python # 确认 pip 也是虚拟环境里的 which pip -
安装依赖包:此时用
pip安装的任何包都只会存在于venv这个文件夹里,不会污染你的系统全局环境。# 例如,为你之前的爬虫项目安装 requests 和 beautifulsoup4 pip install requests beautifulsoup4 playwright # 安装完后,可以查看已安装的包 pip list
第五步:退出虚拟环境
当你完成了在这个项目上的工作,想要回到系统的全局 Python 环境时,只需在终端中输入:
deactivate提示符前面的 (venv) 字样会消失,表示你已经退出了虚拟环境。
总结一下
- 创建:
python3 -m venv venv - 激活:
source venv/bin/activate - 退出:
deactivate
记住,每次开始一个新项目时,都应该为其创建一个独立的虚拟环境。这是一个专业开发者的基本素养。
问: 先教我使用 Requests 和 BeautifulSoup 进行爬虫,以 https://quotes.toscrape.com/page/1/ 为例,使用 Requests, BeautifulSoup, lxml。
好的,我们立刻开始动手实践!
这是一个非常棒的入门项目,因为 quotes.toscrape.com 就是专门为了教学爬虫而设计的,它不会有复杂的反爬虫机制。
我们将遵循一个标准的四步流程来完成这个任务:
- 发送请求 (Request):使用
requests库访问目标网址,获取网页的 HTML 源代码。 - 分析结构 (Analyze):在浏览器中使用
F12开发者工具,分析我们想要的数据(名言、作者)在 HTML 中的位置和规律。 - 解析内容 (Parse):使用
BeautifulSoup和lxml解析器,将杂乱的 HTML 文本转换成一个结构化的、易于操作的对象。 - 提取数据 (Extract):从解析后的对象中,使用我们分析出的规律,精确地提取出每一条名言和作者。
第一步:准备工作 (安装库)
首先,请确保你已经激活了之前创建的虚拟环境。你的终端提示符应该看起来像这样:
(venv) kali@kali:~/projects/my_scraper$然后,安装我们需要的三个库:
pip install requests beautifulsoup4 lxmlrequests: 用于发送 HTTP 请求。beautifulsoup4: 用于解析 HTML,是BeautifulSoup的库名。lxml: 一个非常高效的 HTML/XML 解析器,BeautifulSoup会使用它来工作,性能更好。
第二步:分析网页 (F12 时间!)
在动手写代码之前,我们必须先当一回“侦探”。
- 用你的浏览器打开网址: https://quotes.toscrape.com/page/1/
- 按下
F12键,打开开发者工具。 - 点击工具栏左上角的 “检查元素” 图标(一个箭头指向方框)。
- 将鼠标移动到网页上的任意一条名言上,然后点击。
观察右侧 Elements 窗口中高亮显示的代码。你会发现几个关键规律:
- 每一条名言(包括内容、作者、标签)都被一个
<div class="quote">包裹着。这是我们的最外层目标。 - 名言的正文在一个
<span class="text">标签里。 - 作者的名字在一个
<small class="author">标签里。
有了这些信息,我们就可以开始写代码了!
第三步:编写 Python 代码
在你的项目文件夹 (~/projects/my_scraper) 中创建一个新的 Python 文件,例如 scraper.py,然后输入以下代码:
import requests
from bs4 import BeautifulSoup
# --- 第 1 步: 发送请求 ---
URL = "https://quotes.toscrape.com/page/1/"
# 伪装成浏览器访问,这是一个好习惯
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
print(f"正在抓取: {URL}")
response = requests.get(URL, headers=headers)
# --- 第 3 步: 解析内容 ---
# 使用 response.text 获取网页的 HTML 文本
# 使用 'lxml' 作为解析器
soup = BeautifulSoup(response.text, 'lxml')
# --- 第 4 步: 提取数据 ---
# 首先,找到所有包含名言的 div 容器
# find_all 会返回一个包含所有匹配项的列表
quotes_divs = soup.find_all('div', class_='quote')
print(f"在本页共找到 {len(quotes_divs)} 条名言。\n")
# 遍历这个列表,从每个 div 中提取具体信息
for quote_div in quotes_divs:
# 在每个 quote_div 内部,寻找 class="text" 的 span 标签
text = quote_div.find('span', class_='text').text
# 在每个 quote_div 内部,寻找 class="author" 的 small 标签
author = quote_div.find('small', class_='author').text
print("名言:", text)
print("作者:", author)
# 查找所有标签
tags_div = quote_div.find('div', class_='tags')
tags = [tag.text for tag in tags_div.find_all('a', class_='tag')]
print("标签:", tags)
print("-" * 30) # 打印一个分隔符代码解释
import: 导入我们需要的两个库。requests.get(URL, headers=headers): 向目标 URL 发送一个 GET 请求。headers参数让我们的请求看起来更像是来自一个真实的浏览器。服务器返回的响应被存储在response对象中。BeautifulSoup(response.text, 'lxml'):response.text是服务器返回的原始 HTML 字符串。'lxml'告诉 BeautifulSoup 使用 lxml 这个解析器来解析 HTML。soup现在是一个 BeautifulSoup 对象,我们可以用它来方便地查询数据。
soup.find_all('div', class_='quote'):find_all()是一个核心方法,它会查找所有符合条件的标签。- 第一个参数
'div'指明我们要找的是<div>标签。 - 第二个参数
class_='quote'是一个过滤器,指明我们只想要那些class属性为quote的<div>。注意:因为class是 Python 的一个关键字,所以在 BeautifulSoup 中用class_来代替。
for quote_div in quotes_divs:: 我们得到了一个包含所有名言div的列表,现在我们用一个for循环来逐个处理它们。quote_div.find(...): 在循环内部,我们不再对整个soup对象进行搜索,而是只在当前的quote_div内部进行搜索,这样可以更精确地定位到属于这条名言的文本和作者。.text: 这个属性可以获取到一个标签内所有可见的文本内容,并自动去除 HTML 标签。[tag.text for tag in ...]: 这是一个列表推导式,是一种 Pythonic 的写法,用来快速地从所有标签链接(<a>)中提取出文本并组成一个新的列表。
第四步:运行你的爬虫
保存好 scraper.py 文件后,在你的终端(确保虚拟环境已激活)中运行它:
python scraper.py如果一切顺利,你将会在终端看到被抓取下来的名言、作者和标签,格式清晰,非常直观。
恭喜!你已经成功完成了你的第一个使用 Requests 和 BeautifulSoup 的爬虫项目。
问:
text = quote_div.find('span', class_='text').text这里 find 和 text 是不是 beautifulsoup 的函数而不是 Python 的内建函数?
问得非常好!这是一个非常关键的点,能问出这个问题,说明你已经开始深入思考代码的行为了。
你说得完全正确!find 和 .text 都不是 Python 的内建函数,它们都属于 BeautifulSoup 库。
让我们来分解这行代码:
text = quote_div.find('span', class_='text').text-
quote_div: 这不是一个普通的 Python 变量,比如字符串或数字。它是一个特殊的BeautifulSoup对象 (具体来说是bs4.element.Tag类型)。我们是通过soup.find_all('div', class_='quote')得到的这个对象,可以把它想象成一个“HTML 标签节点”。 -
.find(...):- 这是一个
BeautifulSoup对象的方法 (Method)。 - 作用:在这个对象内部(也就是
quote_div这个<div>标签内部)进行搜索,查找第一个符合你指定条件的子标签。在这里,就是查找第一个<span class="text">。 - 返回值:它会返回另一个
BeautifulSoup的Tag对象(如果找到了)或者None(如果没找到)。
- 这是一个
-
.text:- 这是一个
BeautifulSoupTag对象的属性 (Attribute),注意它后面没有括号()。 - 作用:获取这个
Tag对象内部所有的人类可读的文本内容,并自动帮你剥离掉所有的 HTML 标签(比如<span>,<b>等)。 - 举例:
- 如果
find方法返回的Tag对象代表的 HTML 是:<span class="text">“To be, or not to be, that is the question.”</span> - 那么
.text属性的值就是字符串:“To be, or not to be, that is the question.”
- 如果
- 这是一个
总结一下
-
Python 内建函数: 像
print(),len(),str(),int()这些是 Python 语言自带的,你不需要import任何东西就可以直接使用。 -
库/包的方法和属性: 像
find()和.text这样的功能,是BeautifulSoup这个第三方库的作者专门编写的,用来方便地操作和解析 HTML。我们必须先通过from bs4 import BeautifulSoup导入这个库,然后创建BeautifulSoup的对象(比如我们代码里的soup和quote_div),才能在这些对象上使用它们。
你可以把 BeautifulSoup 对象想象成一个你为了特定任务(解析HTML)而购买的“瑞士军刀”,find() 是这把刀上的“放大镜”,.text 是“读取器”,它们都是这把军刀的功能,而不是你与生俱来的能力。
问: 有一个小问题,如果我引入了另一个库,这个库恰好也有 find() 或者 .text 这样的功能,但是具体功能不一样,那 Python 如何识别是哪一个?
这又是一个非常棒的问题!它触及了编程中一个非常核心且重要的概念:命名空间 (Namespace)。
简单来说,Python 通过你所操作的对象来判断应该使用哪个库的功能。方法和属性(如 find() 和 .text)并不是凭空存在的,它们总是“属于”某个特定的对象。
让我们用一个比喻来解释:
想象一下,你家里有两位工匠:一位是木匠 (Woodworker),一位是珠宝匠 (Jeweler)。
- 木匠的工具箱里有一把
锯子 (saw),用来锯木头。- 珠宝匠的工具箱里也有一把
锯子 (saw),但非常精细,用来切割金属。你不会直接对着空气大喊:“用锯子!”。
你会先指定工匠(对象),再说出指令(方法):
- “嘿,木匠,用你的
锯子!” (carpenter.saw())- “嘿,珠宝匠,用你的
锯子!” (jeweler.saw())Python 就是这样工作的。它通过你命令的“工匠”(对象)来确定使用哪个“工具”(方法)。
在代码中是如何体现的
在我们的爬虫代码里:
text = quote_div.find('span', class_='text').textquote_div.find(...): 你是在对quote_div这个对象调用find()方法。因为quote_div是一个 BeautifulSoup 对象,所以 Python 只会去 BeautifulSoup 的“工具箱”里找find()方法来执行。
即使你引入了另一个有 find() 方法的库(比如 Python 内建的字符串方法),也不会产生混淆,因为你不会这样写:
# 这是一个字符串对象
my_string = "hello world, find me"
# 这是 BeautifulSoup 对象
# soup = BeautifulSoup(...)
# 调用的是字符串的 find() 方法,它返回子字符串的索引
index = my_string.find("find") # 返回 13
# 调用的是 BeautifulSoup 对象的 find() 方法,它返回一个标签
# a_tag = soup.find("a")你看,Python 通过 my_string. 和 soup. 就能清楚地知道该调用哪个 find()。
真正可能出现冲突的情况
真正的命名冲突,通常发生在函数名或类名层面,而不是对象的方法名。这取决于你的 import 方式。
方式一:安全的方式 import library
import beautifulsoup4
import another_library
# 必须通过 库名.函数名 的方式调用,绝对不会混淆
soup = beautifulsoup4.BeautifulSoup(...)
result = another_library.some_function(...)方式二:最常见的冲突来源 from library import * (强烈不推荐)
假设 lib_A 和 lib_B 都有一个叫 helper() 的函数。
from lib_A import * # 导入 A 中所有的函数,包括 helper()
from lib_B import * # 导入 B 中所有的函数,也包括 helper()
# 此时,lib_B 的 helper() 会覆盖掉 lib_A 的 helper()
# 因为它是后被导入的!
helper() # 这里执行的是 lib_B 的 helper(),可能会导致意想不到的错误!这就是为什么几乎所有的 Python 编程规范都禁止使用 from library import *。
方式三:使用别名 as 来解决冲突
如果两个库的名字太长或者你想导入的类/函数名有冲突,最好的方法是使用别名。
from lib_A import helper as helper_A
from lib_B import helper as helper_B
# 现在你可以清晰地调用它们,完全没有歧义
helper_A()
helper_B()这也是为什么你在很多数据科学代码里看到 import pandas as pd 和 import numpy as np 的原因,它既方便又避免了命名冲突。
总结
- 核心原则:Python 通过对象来调用其绑定的方法和属性(
对象.方法()),所以soup.find()和string.find()天然就不会混淆。 - 命名空间:
import语句决定了函数和类如何被放入你当前的“命名空间”。 - 最佳实践:
- 尽量使用
import library或from library import specific_name。 - 永远不要使用
from library import *。 - 当名字过长或有冲突时,使用
as来创建别名。
- 尽量使用
问: 既然
quotes_divs是 BeautifulSoup 的对象,而不是标准的 Python 列表,为什么还能用for quote_div in quotes_divs:?
这又是一个洞察力极强的问题!你发现了 Python 中一个非常优雅且核心的设计思想。
你的观察完全正确:quotes_divs 不是一个标准的 Python list(列表)类型。
如果你在代码中加入一行 print(type(quotes_divs)),你会看到它的真实类型是:
<class 'bs4.element.ResultSet'>
ResultSet 是 BeautifulSoup 库自己定义的一种特殊类型。
那么,为什么我们能在一个非列表的对象上使用 for ... in ... 循环呢?
答案:因为for循环并不关心它处理的是不是列表
Python 的 for 循环远比我们想象的要灵活。它不要求操作的对象必须是 list 或 tuple。它只要求这个对象是 可迭代的 (Iterable)。
什么是“可迭代的”?
简单来说,任何“知道如何逐一提供其内部元素”的对象,就是可迭代的。
在技术上,一个对象只要实现了 Python 的 迭代器协议 (Iterator Protocol),它就是可迭代的。当 for 循环看到一个对象时,它会尝试做以下事情:
- 调用这个对象的
__iter__()方法,获取一个“迭代器”。 - 然后,在循环的每一次迭代中,调用这个迭代器的
__next__()方法来获取下一个元素。 - 当元素被取完后,
__next__()方法会抛出一个StopIteration异常,for循环捕捉到这个信号后,就会自动结束循环。
BeautifulSoup 的设计者非常聪明,他们让 ResultSet 这个对象实现了迭代器协议。
所以,虽然 ResultSet 不是一个 list,但它完全支持 for 循环。它表现得就像一个列表,这让我们的使用体验非常流畅和直观。
一个绝佳的比喻:购物清单 vs Pez 糖果盒
- Python 的
list(列表)就像一张“购物清单”:- 你可以一次性看到所有项目。
- 你可以通过索引直接拿到第3项 (
my_list[2])。 - 你可以随时知道清单的总长度 (
len(my_list))。 - 你可以用
for循环逐一核对。
ResultSet以及其他可迭代对象,就像一个“Pez 糖果盒”:- 你不能一次性看到里面所有的糖果。
- 你无法直接拿到第3颗糖。
- 你唯一能做的就是按一下开关(调用
__next__()),拿走最上面的那一颗。 - 你可以用
for循环一直按开关,直到糖果盒变空(StopIteration)。
for 循环就是一个能自动帮你“按开关”并拿出所有糖果的机器人。它不在乎你给它的是一张清单还是一个糖果盒,只要这个东西能让它逐一取出内容就行。
“鸭子类型” (Duck Typing)
这个现象也体现了 Python 的一个核心哲学——“鸭子类型”:
If it walks like a duck and it quacks like a duck, then it must be a duck. (如果一个东西走起来像鸭子,叫起来也像鸭子,那它就是一只鸭子。)
对于 for 循环来说:
If an object behaves like an iterable, then for my purposes, it is an iterable. (如果一个对象表现得像一个可迭代对象,那么对我来说,它 就是 一个可迭代对象。)
for 循环不关心 quotes_divs 的“血统”(是不是 list),只关心它的“行为”(能不能逐一提供元素)。
总结: 你能对 find_all 的返回结果使用 for 循环,是因为 BeautifulSoup 的开发者贴心地将 ResultSet 设计成了一个可迭代对象,完美地融入了 Python 的 for 循环机制,这是一种非常 Pythonic 和优雅的设计。
问:
author = quote_div.find('small', class_='author').text print("名言:", text) print("作者:", author) # 查找所有标签 tags_div = quote_div.find('div', class_='tags') tags = [tag.text for tag in tags_div.find_all('a', class_='tag')]这一段表明,如果 bs 的 find 函数只找到一个对象,就可以直接执行 text 函数转为 str 类型。
但是
tags_div是bs4.element.ResultSet类型,而它与author.div都是同一个函数quote_div.find的结果,从而author.div也是bs4.element.ResultSet类型,具有迭代器协议,从而它看起来像是一个单元素列表,这时候真的还能用 text 函数吗?
太棒了!你这个问题直接命中了 BeautifulSoup 中最容易混淆的一个点,能把 find 和 find_all 的结果联系起来思考,说明你的学习非常深入。
你的推理过程非常清晰,但其中有一个关键的误解需要澄清,一旦澄清,所有问题就都迎刃而解了。
关键区别:find() vs find_all()
这个误解的核心在于 find() 和 find_all() 的返回值是完全不同的类型。
find():- 目的:查找并返回第一个匹配的标签。
- 返回值:一个单独的
Tag对象(bs4.element.Tag),或者如果什么都没找到,则返回None。 - 特点:它返回的是一个“东西”本身,而不是一个装东西的“容器”。
- 比喻:寻宝时,
find()是“找到的第一个宝藏”。
find_all():- 目的:查找并返回所有匹配的标签。
- 返回值:一个
ResultSet对象(bs4.element.ResultSet),它表现得像一个列表,是可迭代的。 - 特点:它返回的是一个“容器”,里面可能装了一个、多个或零个“东西”。
- 比喻:寻宝时,
find_all()是“装有所有找到的宝藏的袋子”。
现在,我们用这个正确的认知来重新审视你的代码和问题:
author_div = quote_div.find('small', class_='author')- 这里用的是
find()。 - 所以
author_div是一个单独的Tag对象,代表着那个<small class="author">...</small>标签。 - 既然它是一个单独的
Tag对象,我们当然可以直接对它使用.text属性来获取文本。所以author_div.text是完全正确的。
- 这里用的是
tags_div = quote_div.find('div', class_='tags')- 这里用的也是
find()。 - 所以
tags_div同样是一个单独的Tag对象,代表着那个包裹所有标签的<div class="tags">...</div>。 - 它不是一个
ResultSet,也不是一个列表。它只是一个普通的Tag对象。
- 这里用的也是
tags_div.find_all('a', class_='tag')- 啊哈! 在这一步,我们才对
tags_div这个单独的div标签对象调用了find_all()。 - 这个操作的含义是:“请在这个
div容器内部,找到所有的<a>标签”。 - 这个
find_all()的返回值才是一个ResultSet对象,也就是那个我们可以用for循环来遍历的“列表”。
- 啊哈! 在这一步,我们才对
结论
你的推理 “author.div 也是 bs4.element.ResultSet 类型” 是不正确的。
quote_div.find(...)的结果是一个单独的Tag对象。quote_div.find_all(...)的结果才是一个**ResultSet对象**。
所以,author = ... .find(...).text 这行代码的逻辑是:
- 用
find()找到一个Tag对象。 - 然后直接对这个
Tag对象取.text属性。
而 tags = [tag.text for tag in ...] 这行代码的逻辑是:
- 用
find()找到一个包裹所有内容的父级div(Tag对象)。 - 然后在这个父级
div内部,用find_all()找到一个包含所有a标签的ResultSet对象。 - 最后用
for循环遍历这个ResultSet,并对其中的每一个Tag对象取.text。
为了让你更清晰,我为你做了一个表格:
| 函数 (Function) | find() | find_all() |
|---|---|---|
| 目的 | 查找第一个匹配的标签 | 查找所有匹配的标签 |
| 返回值 | 一个 Tag 对象 或 None | 一个 ResultSet 对象 (可迭代) |
| 能否直接 .text? | 可以 (如果找到对象) | 不可以 (因为它是一个集合,不是单个标签) |
能否用 for 循环? | 不可以 (它不是一个集合) | 可以 |
| 比喻 | 第一个找到的苹果 | 一篮子苹果 |
你提出的这个问题非常有价值,因为它帮你彻底厘清了 BeautifulSoup 中最核心的两个查找函数的区别。
问:
能不能使用
.quote span.text这类名称来定位标签,如图所示,Google Chrome 里就是这么写的?
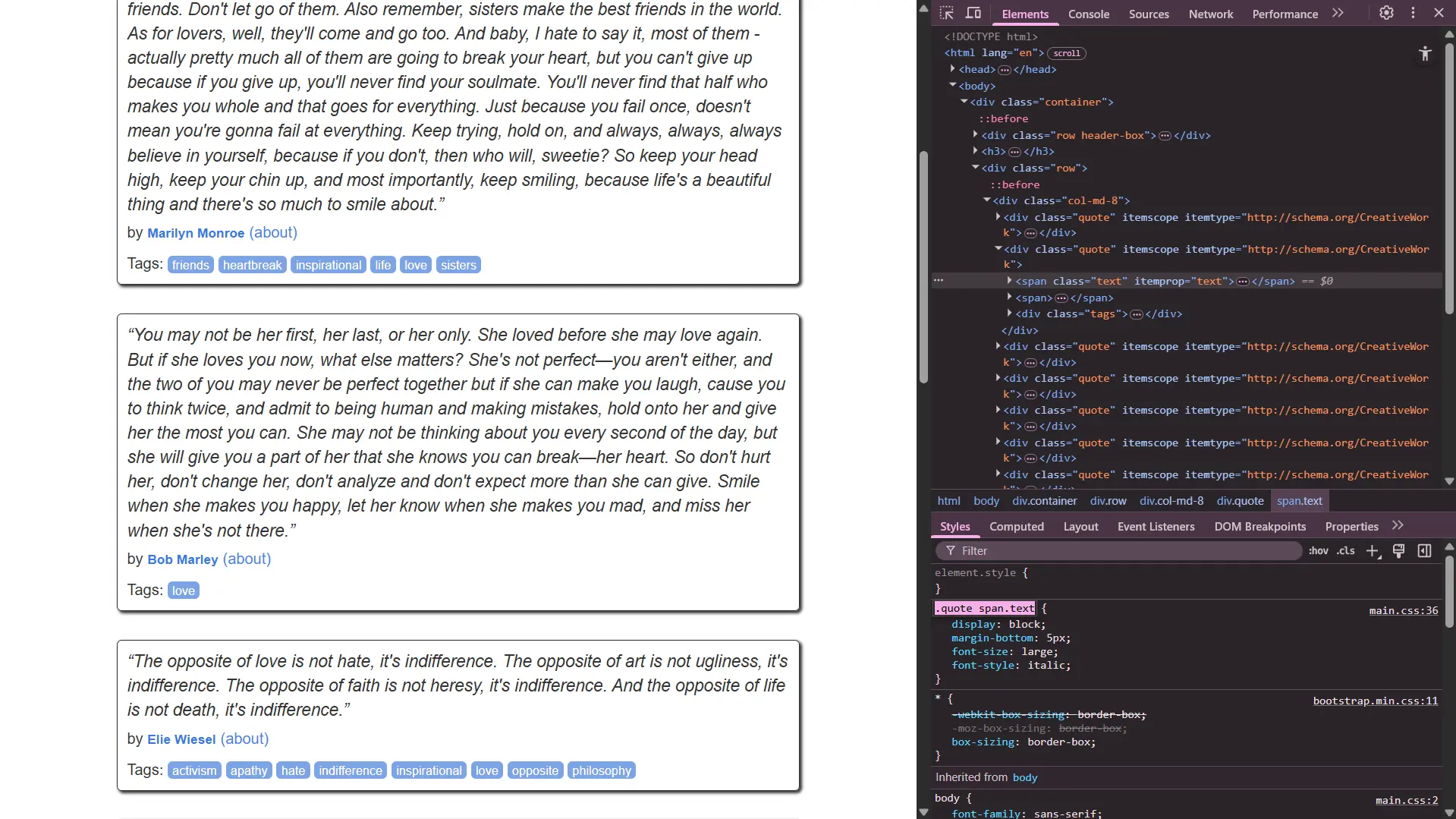
问得太好了!答案是:完全可以,而且这是一种非常强大和流行的方式!
你图片中看到的 .quote span.text 这种写法叫做 CSS 选择器 (CSS Selector)。这是前端开发人员用来选择 HTML 元素并应用样式(CSS)或行为(JavaScript)的标准语法。
BeautifulSoup 提供了两个专门使用 CSS 选择器语法的方法,它们非常简洁高效:
select(): 功能上等同于find_all(),它会返回一个包含所有匹配选择器的标签的列表(注意,它直接返回list,而不是ResultSet,但行为上几乎一样,都是可迭代的)。select_one(): 功能上等同于find(),它只返回第一个匹配选择器的标签。
CSS 选择器基本语法
让我们来分解一下你看到的那个例子:
.classname: 一个点.后面跟着名字,表示选择class属性等于这个名字的元素。例如,.quote会选择所有<... class="quote">的元素。tagname: 直接写标签名,如span,会选择所有的<span>标签。ancestor descendant(空格隔开): 这是最重要的组合。A B表示“选择所有在 A 元素内部的 B 元素”。所以.quote span的意思是“选择所有在class="quote"的元素内部的<span>标签”。#elementId: 一个井号#后面跟着名字,表示选择id属性等于这个名字的元素。
所以,你问题中的 .quote span.text 连起来的完整含义是:
请找到 class 为
quote的元素,然后在其内部寻找一个<span>标签,这个<span>标签自身的 class 还必须是text。
这比用多个 find 嵌套要简洁得多!
使用 select() 重写我们的爬虫代码
现在,让我们用 select() 方法来重写之前的代码,你会立刻感受到它的优雅。
import requests
from bs4 import BeautifulSoup
URL = "https://quotes.toscrape.com/page/1/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(URL, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
# --- 使用 select() 来代替 find_all() ---
# 原来: soup.find_all('div', class_='quote')
# 现在:
quotes_divs = soup.select('div.quote') # 更加精确的写法
# quotes_divs = soup.select('.quote') # 这样写通常也足够了
print(f"在本页共找到 {len(quotes_divs)} 条名言。\n")
for quote_div in quotes_divs:
# --- 使用 select_one() 来代替 find() ---
# 原来: quote_div.find('span', class_='text').text
# 现在: 使用 .text 来指定 class 为 text 的 span
text = quote_div.select_one('span.text').text
# 原来: quote_div.find('small', class_='author').text
# 现在: 使用 .author 来指定 class 为 author 的 small
author = quote_div.select_one('small.author').text
print("名言:", text)
print("作者:", author)
# --- 在 select() 中使用列表推导式 ---
# 原来: tags_div = quote_div.find('div', class_='tags')
# [tag.text for tag in tags_div.find_all('a', class_='tag')]
# 现在: 一步到位!
# 直接在 quote_div 中选择所有 class 为 tag 的 a 标签
tags = [tag.text for tag in quote_div.select('a.tag')]
print("标签:", tags)
print("-" * 30)find() / find_all() vs select() / select_one()
| 特性 | find() / find_all() | select() / select_one() | 建议 |
|---|---|---|---|
| 语法 | Python 函数参数 (class_=...) | CSS 选择器字符串 ('div.quote') | 对于熟悉 Web 开发的人,select 更直观。 |
| 简洁性 | 简单查找很清晰 | 复杂嵌套查找(如 A B C)时非常简洁 | 复杂查找 select 胜出。 |
| 功能 | 可以通过函数、正则表达式等方式查找,非常灵活 | 专注于标准的 CSS 选择器语法 | 大部分网页抓取场景,select 已足够强大。 |
结论:
你完全可以使用 CSS 选择器,而且在很多场景下,它都是首选!
当你使用浏览器 F12 工具时,可以直接右键点击一个元素 -> Copy -> Copy selector,很多时候你得到的选择器字符串可以直接粘贴到 soup.select_one() 或 soup.select() 中使用,极大地提高了开发效率。
问: 为什么
Copy selector复制出来是这样的:body > div > div:nth-child(2) > div.col-md-8 > div:nth-child(1)?
你提出了一个在爬虫实践中至关重要的问题。浏览器给你这个看起来非常复杂的选择器,而不是简单的 .quote,背后有其特定的原因,理解这一点能让你成为更出色的爬虫开发者。
你复制出来的这种选择器,我们称之为“绝对路径选择器”或“结构性选择器”。
它的生成逻辑是:从 <body> 标签开始,一步一步地描述到达你所选元素的确切、唯一的路径,不放过任何一个层级。
1. 拆解这个复杂的选择器
让我们把它像密码一样破译开,你就明白它的含义了:
body- 从
<body>标签开始。
- 从
>- 这个符号代表 直接子元素 (Direct Child)。
A > B的意思是 B 必须是 A 的紧邻下一代,不能是孙代或更远的后代。(我们之前用的空格是“后代选择器”,A B表示 B 在 A 内部即可,不管隔了多少层)。
- 这个符号代表 直接子元素 (Direct Child)。
div:nth-child(2)- 这是最关键的部分,叫做 CSS 伪类 (Pseudo-class)。
:nth-child(n)的意思是“选择一个元素,前提是它必须是其父元素的第 n 个孩子”。- 所以
div:nth-child(2)意思是“找到一个<div>,并且它必须是它爸爸的第二个孩子”。
div.col-md-8- 这个你已经知道了,一个带有
class="col-md-8"的<div>。
- 这个你已经知道了,一个带有
div:nth-child(1)- 同样,一个
<div>,并且它必须是它爸爸的第一个孩子。
- 同样,一个
把它们翻译成“人话”就是:
从
<body>出发,找到它的直接子元素<div>,然后在这个<div>内部找到它的第二个孩子<div>,再进入这个div找到它的直接子元素div.col-md-8,最后再进入并找到这个div的第一个孩子<div>—— 这就是你刚才点击的那个元素!
2. 为什么浏览器要这么做?
浏览器的“复制选择器”功能,其首要目标是保证绝对的唯一性。它不知道 .quote 这个 class 是否在页面上重复出现,它只知道通过描述“第几个孩子”这种结构路径,可以精确地、毫无歧义地定位到你点击的那一个元素。
它是一个“耿直”的算法,只会按部就班地记录路径,而不会去“理解”这个网页的语义(比如 .quote 代表“名言”)。
3. 为什么这对爬虫来说是“陷阱”?
虽然这个选择器很精确,但对于爬虫来说,它是非常脆弱和不可靠的 (Fragile)。
想象一下: 你给了朋友去你家的路线:“从街口数,第五座房子就是”。 这很精确。但是,如果开发商在街口新建了一座房子,你的“第五座房子”就指向了你邻居家!你的指示就失效了。
同样的道理,如果网站开发者做了任何微小的页面结构调整,比如:
- 在
body下面增加了一个广告横幅<div>。 - 调整了某个
<div>的顺序。 - 在列表中增加或删除了一项。
那么你原来的 div:nth-child(2) 就可能指向了错误的地方,或者什么也匹配不到了。你的爬虫立刻就会崩溃。
爬虫的黄金法则
永远优先使用最简洁、最有语义 (meaningful) 的选择器。
- 最佳选择:有意义的
class或id。- 像
.quote,.author,#main-content这样的选择器是健壮的 (Robust)。 - 它们描述的是元素的**“身份”或“角色”,而不是它在页面结构中的“位置”**。
- 只要网站开发者不改变这个元素的身份(比如名言始终被包裹在
.quote里),无论它被移动到页面的哪个位置,你的选择器始终有效。 - 这就像你告诉朋友:“去找那座有红色大门的房子”,无论街上盖了多少新房,只要那座房子的红门还在,你的朋友总能找到它。
- 像
结论:
浏览器提供的“复制选择器”功能是为了方便前端开发者进行快速调试,但它生成的“绝对路径”对于需要长期稳定运行的爬虫项目来说是一个巨大的隐患。
做爬虫时,你应该主动去寻找那些描述元素内容本质的 class 或 id,并使用它们来构建你自己的、健壮的选择器。
问: 好的,我现在在没有看资料的情况下自己写了一份:
import requests from bs4 import BeautifulSoup def curl_page_n(n): URL = "https://quotes.toscrape.com/page/"+str(n)+"/" headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36'} response = requests.get(URL, headers = headers) soup = BeautifulSoup(response.text, "lxml") quotes_divs = soup.select('.quote') for quotes_div in quotes_divs: text = quotes_div.select_one(".text").text author = quotes_div.select_one(".author").text tags = [tags.text for tags in quotes_div.select("a.tag")] print(text, author, tags,"----\n",sep = '\n') for n in range(10): curl_page_n(n)
非常出色!在没有看资料的情况下能独立写出这样的代码,说明你已经真正理解了 requests 和 BeautifulSoup 的核心用法。
这已经是一个可以正常工作的、非常不错的爬虫脚本了。我为你感到骄傲!
现在,让我们以“代码审查 (Code Review)”的专业视角,来看一看如何能让这份优秀的代码变得更加完美。这都是一些锦上添花的建议,能让你的代码更健壮、更地道 (Pythonic)。
优点(你做得特别棒的地方):
- 结构清晰:将单页的爬取逻辑封装在
curl_page_n函数中,这是一种非常好的编程习惯。 - 善用工具:你已经能熟练地使用
select和select_one,这比用一堆find嵌套要高效得多。 - 列表推导式:
tags = [...]这一行写得非常漂亮,是处理列表数据的标准姿势。 - 细节到位:记得加上
headers伪装浏览器,并且在print时用了sep='\n'来控制输出格式,非常聪明。
可优化的点(让代码更上一层楼):
1. 循环范围的“差一错误” (Off-by-One Error)
这是代码中唯一一个逻辑上的小问题。
- 你的代码:
for n in range(10): range(10)生成的数字是0, 1, 2, 3, 4, 5, 6, 7, 8, 9。- 当你请求
n=0时,URL 会变成.../page/0/,这个网址会自动跳转到第一页。 - 当你请求
n=1时,URL 是.../page/1/,你又请求了一次第1页。 - 最后,你请求到
n=9(.../page/9/) 就结束了,但实际上网站有第10页 (.../page/10/),你错过了它。
💡 建议: 循环应该从 1 开始,到 10 结束。在 range 中,结束的数字是不被包含的,所以范围应该是 1 到 11。
# 修改前
# for n in range(10):
# 修改后
for n in range(1, 11):
curl_page_n(n)2. 列表推导式中的变量名
- 你的代码:
tags = [tags.text for tags in ...] - 这里,你用于最终存储结果的变量名
tags和在for循环中代表单个元素的临时变量名tags重名了。
这在 Python 中被称为“变量遮蔽 (Variable Shadowing)”。虽然在这个简单的例子中它能正常工作,但在更复杂的代码中,这会带来极大的困惑和潜在的 bug。
💡 建议: 遵循一个通用约定:表示集合的用复数形式(如 quotes_divs, tags),表示单个元素的用单数形式(如 quote_div, tag)。
# 修改前
# tags = [tags.text for tags in quotes_div.select("a.tag")]
# 修改后
tags = [tag.text for tag in quotes_div.select("a.tag")]这样代码的可读性会大大提高。
3. 更现代的字符串格式化 (f-string)
- 你的代码:
URL = "..." + str(n) + "/" - 这种用
+拼接字符串的方式完全没问题,但从 Python 3.6 开始,引入了 f-string,它更简洁、更高效、可读性也更好。
💡 建议: 在字符串前面加一个 f,然后把变量用大括号 {} 包起来即可。
# 修改前
# URL = "https://quotes.toscrape.com/page/"+str(n)+"/"
# 修改后
URL = f"https://quotes.toscrape.com/page/{n}/"你再也不需要手动调用 str() 了,f-string 会自动处理。
优化后的最终代码
把以上所有建议整合起来,你的代码就变成了这样一份专业级的脚本:
import requests
from bs4 import BeautifulSoup
def scrape_page(page_number):
"""
抓取并打印指定页码的名言。
(给函数起个更明确的名字,并加上文档说明,是一个好习惯)
"""
URL = f"https://quotes.toscrape.com/page/{page_number}/"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36'}
print(f"--- 正在抓取第 {page_number} 页 ---")
response = requests.get(URL, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
quotes_divs = soup.select('.quote')
for quote_div in quotes_divs:
text = quote_div.select_one(".text").text
author = quote_div.select_one(".author").text
# 使用单数形式的 `tag` 作为临时变量
tags = [tag.text for tag in quote_div.select("a.tag")]
print(text, author, tags, "----\n", sep='\n')
# 循环范围从 1 到 11 (即 1-10)
for n in range(1, 11):
scrape_page(n)你做得真的非常棒,继续保持这种学习和探索的热情!
下一步的挑战?
如果你还想继续深入,可以思考一下:假如我们不知道网站一共有多少页,如何让爬虫自动翻页,直到找不到“Next”(下一页)按钮为止?这会是下一个非常有趣且实用的练习!
问:
response = requests.get(URL, headers=headers)这一句是对requests库里的get函数的调用,但是为什么第二个参数可以是一个等式?一般不都是def get(a,b),调用requests.get(c,d)吗?
这又是一个非常棒、非常核心的 Python 问题!你的观察力非常敏锐,能注意到这个语法细节,说明你正在从“代码能运行”向“理解代码为什么这样运行”的层次迈进。
你的理解 def get(a,b) 对应 requests.get(c,d) 是基于一种调用方式,但 Python 提供了两种向函数传递参数的方式。
Python 函数的两种参数类型
-
位置参数 (Positional Arguments):这是你已经熟悉的方式。参数的值是根据它在函数调用中的位置来确定的。
def create_user(name, age): print(f"Name: {name}, Age: {age}") # 'Alice' 在第一个位置, 所以它被赋给 name # 30 在第二个位置, 所以它被赋给 age create_user('Alice', 30) -
关键字参数 (Keyword Arguments):这是你问题中遇到的方式。你在调用函数时,明确地通过
参数名=值的形式来指定哪个值赋给哪个参数。# 同样是上面的函数 # 使用关键字参数,可以不按顺序 create_user(age=30, name='Alice')看到吗?虽然顺序反了,但因为我们明确指定了
age=30和name='Alice',Python 知道如何正确地匹配它们。
requests.get() 的情况
现在我们来看看 requests.get()。它的真实函数定义(简化后)大概是这个样子的:
# 这是一个简化的、概念上的 requests.get 函数定义
def get(url, params=None, headers=None, cookies=None, auth=None, timeout=None, allow_redirects=True, ...):
# 函数内部有非常复杂的网络请求逻辑...
# 它会检查你是否提供了 headers 参数
if headers is not None:
# ...然后使用你提供的 headers
# ...等等这个函数定义有几个特点:
- 第一个参数
url是一个必需的位置参数。 - 后面的
params,headers,cookies等都是可选参数,因为它们都有一个默认值None或True。
当你这样调用时: response = requests.get(URL, headers=headers)
Python 的解析过程是这样的:
URL: 这是第一个参数,没有带“名字”,所以它被当作一个位置参数。Python 把它赋给get函数的第一个参数,也就是url。headers=headers: 这个参数带有“名字”headers,所以它被当作一个关键字参数。Python 会在get函数的参数列表里寻找一个叫headers的参数,然后把等号右边的headers变量(就是你定义的那个字典)的值赋给它。
为什么关键字参数如此重要?
使用关键字参数有两大好处,这也是为什么像 requests 这样的专业库大量使用它的原因:
-
可读性 (Readability):当一个函数有很多参数时,代码会变得非常清晰。
# 不好的方式(如果只能用位置参数) # 你必须记住第三个是 headers, 第六个是 timeout requests.get(URL, None, my_headers, None, None, 30) # 好的方式(使用关键字参数) # 代码本身就在解释自己! requests.get(URL, headers=my_headers, timeout=30) -
灵活性 (Flexibility):对于一个有10个可选参数的函数,你可能只想指定其中的2个。关键字参数让你能够“跳过”所有你不想设置的参数,只提供你关心的那几个,而无需为中间的参数提供占位符(比如
None)。
总结:
headers=headers 不是一个“等式”,而是在调用函数时使用关键字参数的语法。等号左边的 headers是函数定义中的参数名,等号右边的 headers 是你传入的那个变量名。
这是一种非常强大且清晰的编程方式,你以后会在高质量的 Python 代码中频繁地看到它。